Say for example the application has been written with performance in mind, all queries are optimal, no index issues, databases are fully optimized through a nightly job or manually, and the best I/O subsystem has been deployed to achieve excellent I/O throughput.

This is one of the “pulling hair” type situations to figure out the root causes. This article is for DBAs and Sys Admins who are running SQL Server in physical or in a virtual environment and experiencing slow I/O response.
Detecting I/O Issues with SQL DMV:
To check for outstanding IOPs waiting longer than 10ms:
SELECT *
FROM sys.dm_io_pending_io_requests
WHERE io_type='disk'
ANDio_pending_ms_ticks> 10
To check the time spent waiting on PAGEIOLATCH_*:
SELECT SUM(wait_time_ms)total_wait_ms
FROM sys.dm_os_wait_stats
WHERE wait_typeLIKE'PAGEIOLATCH%'
What to check?
There are some areas that need to be checked to see whether there is a misconfiguration or not.
1. NTFS Allocation Unit (formerly known as cluster size)2. Volume Alignment (also known as disk, partition or sector alignment)
3. HBA Disk Queue Depth
HBA Disk Queue Depth:
HBA Disk Queue Depth is another area which is often/always left as default (ranging from 8 to 32). This setting also needs to be reviewed based on workload. Inappropriate settings can significantly impact I/O throughput and out-of-the box values can be insufficient for SQL Server.Although a testing is required to determine optimal value of HBA Disk Queue Depth for a particular workload; however queues depth of 64 is generally accepted as a good starting point in the absence of any specific vendor recommendations.
NTFS File allocation unit size (cluster size):
Often, the file allocation unit size (cluster size) is not taken into consideration while formatting a SQL Data drive (physical and virtual). It is highly recommended that all SQL Server data drives should be 64KB. "The best practice for SQL Server is to choose 64KB, because this reduces the likelihood of I/O’s that span distinct NTFS allocations, which then might result in split I/O’s." Eventually this introduces significant disk latency.
In SQL Server, each page size is 8KB, and eight (8) physically contiguous pages (8KB X 8 = 64KB) create one Extent. Therefore if the NTFS allocation unit size is 64KB then the Extent creation by SQL Server Engine will be hassle free, meaning it does not require extra pointer calculations overhead -which provides an efficient read and write operation.Use the following command to check drive info.
fsutil fsinfo ntfsinfo [your drive]
fsutil fsinfo ntfsinfo [your drive]
How to check Allocation Unit Size?
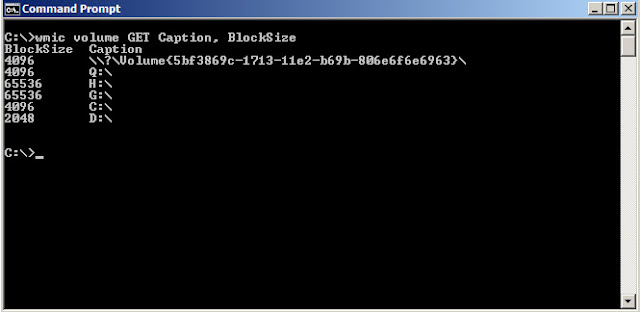
We can use the following command to check the "allocation unit size" of all logical disks. Open the command window and then type,
cmd> wmic volume GET Caption, BlockSize
The above command will provide the following output:
Volume Alignment (Disk Alignment, Sector Alignment or Partition Alignment):
From my experience, I have seen a number of DBAs, sysadmins and storage admins that have no idea what it is all about and what the impact is on the performance.In SQL Server OLTP environment (the DML operation such as SELECT, UPDATE) proper disk alignment will provide up to a 30% -40% dramatic performance improvement. This is clearly documented and explained in various Microsoft articles.
There are a number of sites where this topic has been discussed very elaborately. I encourage you to read those before preparing a disk for SQL Server data files.
Up to Windows 2003, Sector Alignment was not done automatically while formatting and installing Windows OS, it was all manual task which was usually performed by the server admin. This has been changed starting from Windows 2008 Server and later versions. Windows Server 2008 uses 1024 KB (2048 sectors) as a starting offset for the disk which is larger than 4GB, which will usually work well for almost any array.
How to check Volume Alignment?
There are many different methods and as well as tools are available to check volume alignment. Following is the simplest method:
1. Type Msinfo32.exe in the search window in start menu.
2. In the dialog box look for Components > Storage > Disks.
3. Look for the desired logical drive and find the "Partition Starting Offset".
4. The number is divisible by 4096 bytes -
(a) If dividing it by 4096 reveals a whole number then volume alignment is correct.
(b) If dividing it by 4096 gives decimal then the volume alignment is not correct.
Alternatively following command can used to get the same information.
cmd> wmic partition get Index, Name, StartingOffset

Manually adjust alignment for basic disks:
We can use diskpart.exe to format the drive with correct alignment while preparing the Disk for SQL Server data files. Please be careful, following steps erase the selected partition- so don’t try it in a live system.
1. Open a command prompt, then type diskpart
2. Type list disk to check which disks are available
3. Select the desired partition to align:
select disk <DiskNumber>
4. We will Align the partition to 1024KB:
create partition primary align=1024
5. Assign a drive letter to it:
assign letter=<DriveLetter>
6. The volume alignment has set correctly. Now we can format the disk as usual.
Following is a demonstration to show you how to use above diskpart commands to correct volume alignment.

Following is freeware tool (Disk Alignment Test v1.0.1) can also be used to check disk alignment.

Recommendations:
1. When formatting the partition that will be used for SQL Server data files, it is recommended that you use a 64-KB allocation unit size for data, logs, and tempdb.
2. Review and align the sector to 1024KB (or 2048KB max) before formatting the disk
3. Correcting the Allocation Unit Size and Volume Alignment is necessary for Physical and virtual disks for significant I/O performance.
Further Reading:
Disk Partition Alignment Best Practices for SQL Server
Performance Tuning Guidelines for Windows Server 2008
Recommendations for Aligning VMFS Partitions
Disk performance may be slower than expected when you use multiple disks in Windows Server 2003, in Windows XP, and in Windows 2000
Disk Alignment Test